
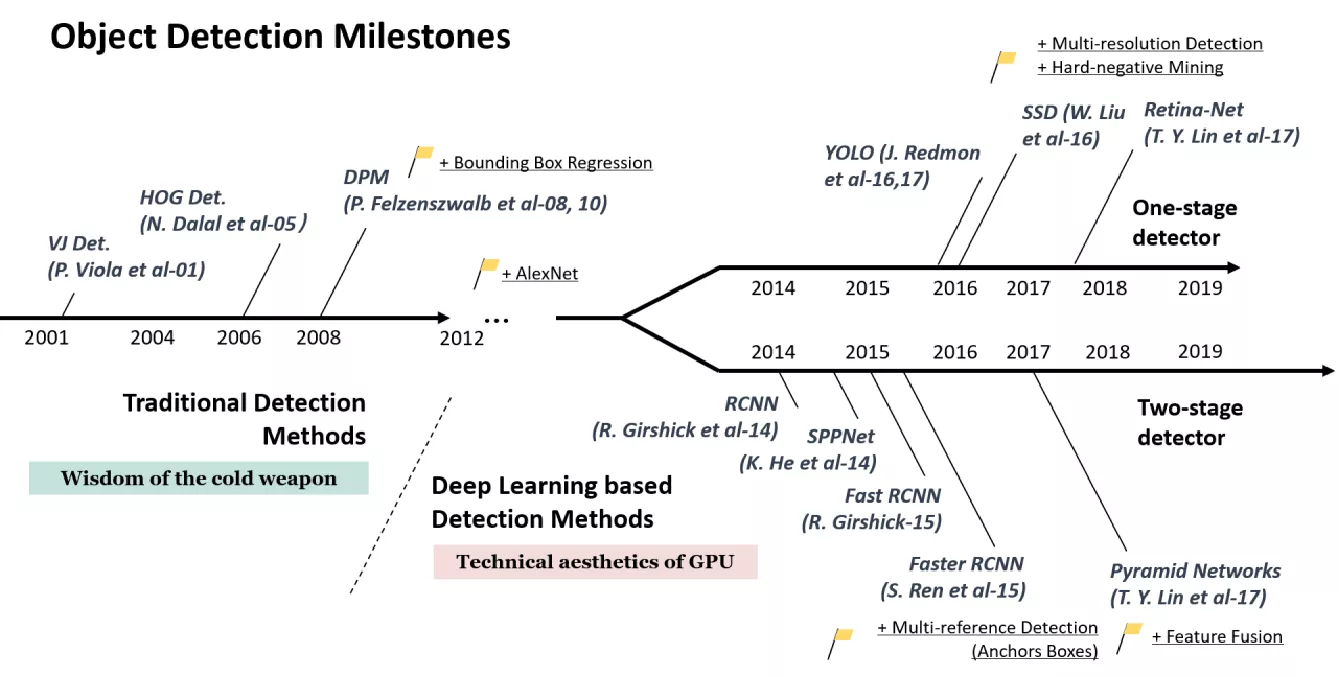
目标检测算法综述
目标检测算法发展历程
 2012年之前,都是传统的目标检测算法,传统的目标检测算法采用类似穷举的滑动窗口方式或图像分割技术来生成大量的候选区域,然后对每一个候选区域提取图像特征(包括HOG、SIFT、 Haar等),并将这些特征传递给一个分类器(如 SVM、Adaboost和 Random Forest等) 用来判断该候选区域的类别.由于传统方法提取的特征存在局限性,产生候选区域的方法需要大量的计算开销,检测的精度和速度远远达不到实际应用的要求这使得传统目标检测技术研究陷入了瓶颈。
2012年后,将深度学习应用在目标检测领域,检测的速度和准确度有个飞速的进步,目标检测开始进去发展的新时期。
2012年之前,都是传统的目标检测算法,传统的目标检测算法采用类似穷举的滑动窗口方式或图像分割技术来生成大量的候选区域,然后对每一个候选区域提取图像特征(包括HOG、SIFT、 Haar等),并将这些特征传递给一个分类器(如 SVM、Adaboost和 Random Forest等) 用来判断该候选区域的类别.由于传统方法提取的特征存在局限性,产生候选区域的方法需要大量的计算开销,检测的精度和速度远远达不到实际应用的要求这使得传统目标检测技术研究陷入了瓶颈。
2012年后,将深度学习应用在目标检测领域,检测的速度和准确度有个飞速的进步,目标检测开始进去发展的新时期。
R-CNN
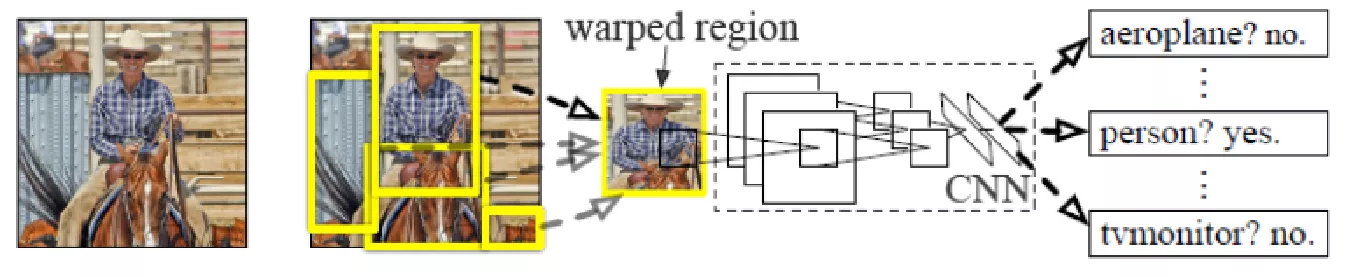
2014 年,Girshick 等人成功将卷积神经网络 ( Convolutional Neural Networks,CNN) 运用在目标检测领域中,提出了R-CNN 算法,它将 AlexNet与选择性搜索( selective search)算法相结合,把目标检测任务分解为若干个独立的步骤。
基本步骤
- 输入图像,利用SS算法在图片中找到2000个候选区域
- 将2000个候选区域进行大小变换,得到固定尺寸227x227,然后输入到神经网络中,进行区域特征提取
- 经过20个类别的SVM分类器,对于2000个候选区域进行判断,得到类别信息
- 对候选区域做NMS,去除不好的,重叠度高的一些候选区域
- 修正候选区域

部分概念
(1)IoU
简单理解就是交并比,即:两个候选框的交集/并集。取值在0和1之间。
(2)NMS
非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,用于目标检测中,就是提取置信度高的目标检测框,而抑制置信度低的误检框。
它的基本步骤是:
1.寻找得分最高的候选框;
2.计算其他候选框与该候选框的IoU值;
3.删除所有IoU值中大于给定阈值的候选框。
IoU值大,说明这两个候选框重叠部分多,说明这两个候选框选定的是同一个目标,所以要删掉得分较低的候选框。
优缺点
优点:
使目标检测的精度得到了质的改变,是将深度学习应用到目标检测领域的里程碑之 作,同时也奠定了基于深度学习的双阶段目标检测算法的基础。
缺点:
选出的区域多数都是互相重叠,重叠部分会被多次重复提取特征,导致重复计算,比较耗时。
SPP-Net
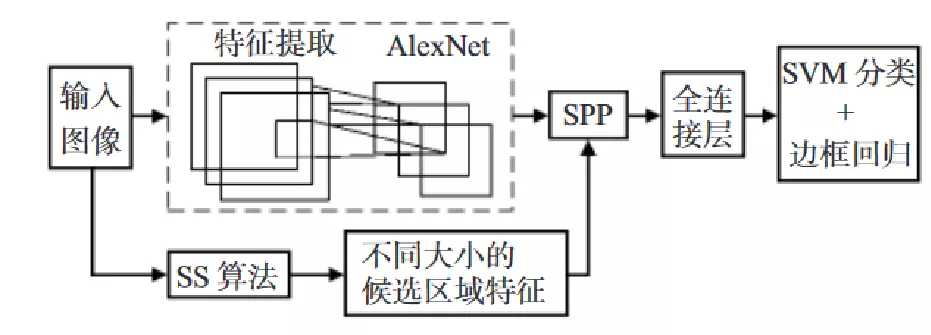
2014 年 He 等人提出了空间金字塔网络( Spatial Pyramid Pooling Network,SPP-Net) 检测算法,它在 CNN 最后一层卷积层和全连接层之间加入 SPP 层,使得网络能够输入任意尺度的候选区域,从而每张输入图片只需一次 CNN 运算,就能得到所有候选区域的特征,这使得计算量大大减少。
基本步骤
- 图片输入网络,得到全图的feature map;
- 原图经过SS算法得到的候选区域直接映射全图的feature map,得到每个候选区域的特征向量;
- 映射出来的候选区域的特征向量经过SSP层,输出固定大小的特征向量给全连接层
优缺点
优点:
引入了空间金字塔,适应各种不同尺寸的特征图;
对整张图进行一次特征提取,加速运算速度,并提出了权重共享的策略。
缺点:
分类器使用SVM,训练依然过慢,效率低;
进行分阶段训练,训练步骤复杂。
Fast R-CNN
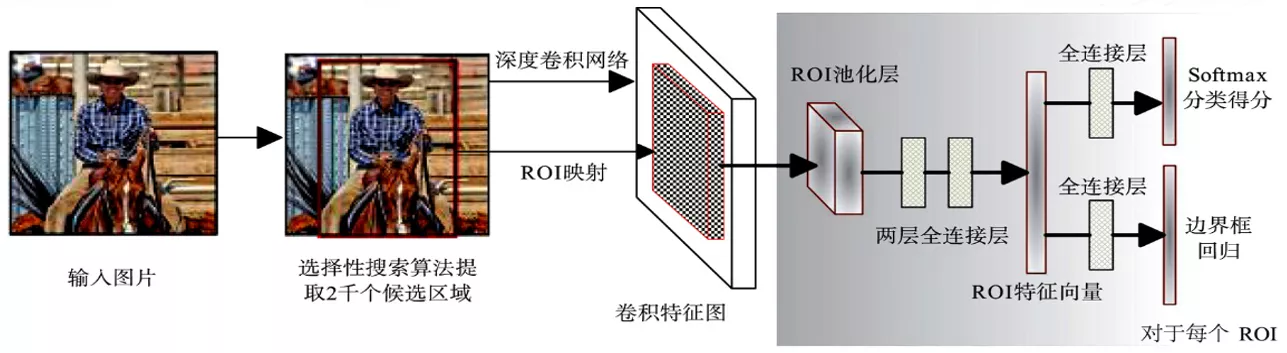
2015 年,Girshick 等人提出了Fast R-CNN算法,他们受到SPP-Net算法的启发,将SPP层简化成单尺度的ROI Pooling 层以统一候选区域特征的大小,而且进一步提出了多任务损失函数思想,将分类损失和边界框回归损失统一训练学习,使得分类和定位任务不仅可以共享卷积特征,还可以相互促进提升检测效果。
基本步骤
- 一张图片经过SS算法生成2k个候选区域
- 整个图像输入卷积神经网络得到整个图像的feature map,将SS算法得到的候选框映射到feature map上得到每个候选区域的特征向量
- 每个特征矩阵通过RoI pooling层缩放到7x7大小的特征图,接着展平特征图送入到一系列的全连接层。
优缺点
优点:
- 使用Softmax去代替SVM进行多分类的预测,从而实现了端到端的训练;
- 引入ROI pooling,速度更快
缺点: - 依然需要SS算法产生候选区域,速度慢。
Faster R-CNN
2015年Ren等人提出了 Faster R-CNN 算法框架 ,设计了辅助生成样本的RPN 取代选择性搜索算法。RPN是一种全卷积神经网络 (FCN) 结构,它将任意大小的特征图作为输入,经过卷积操作后产生一系列可能包含目标的候选区域,使算法实现了端到端的训练。
基本步骤
- 整张图像输入网络得到特征图feature map;
- 使用RPN结构生成候选框,将RPN后生成的候选框映射到特征图上得到每个候选框的特征矩阵;
- 将每个特征矩阵通过RoI pooling,得到7x7大小的特征图,接着展平特征图,通过一系列的全连接层得到预测结果
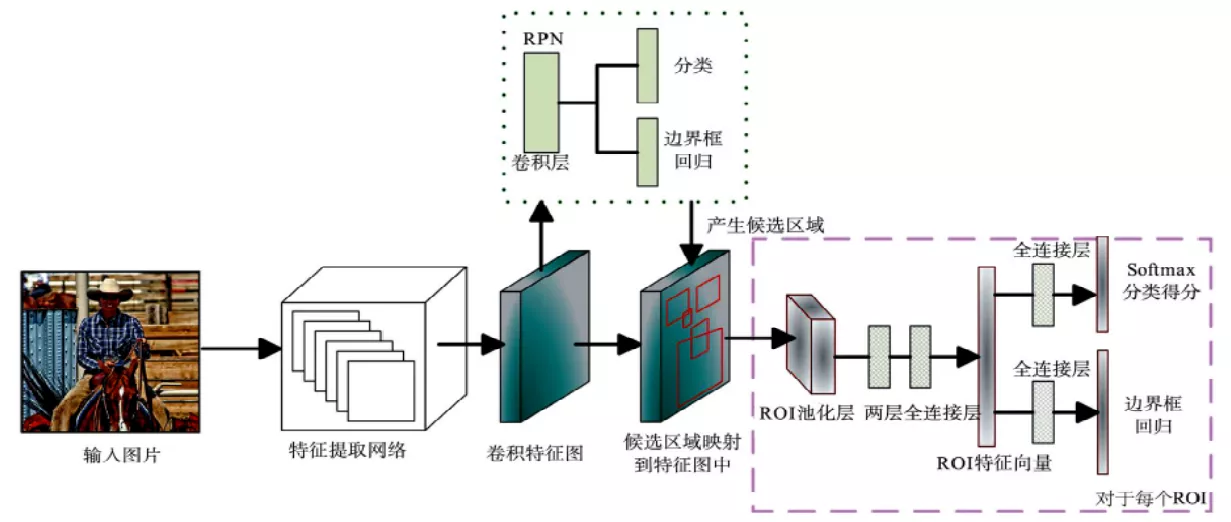
优缺点
优点:
- RPN 的使用,使Faster R-CNN 能够将网络中区域建议、特征提取、分类及定位多个步骤整合到一起,真正成为端到端的训练。
缺点:
- Faster R-CNN特征图上的一个锚点框对应于原图中一块较大区域,因此,Faster R-CNN对小目标检测效果不是很好。
YOLO
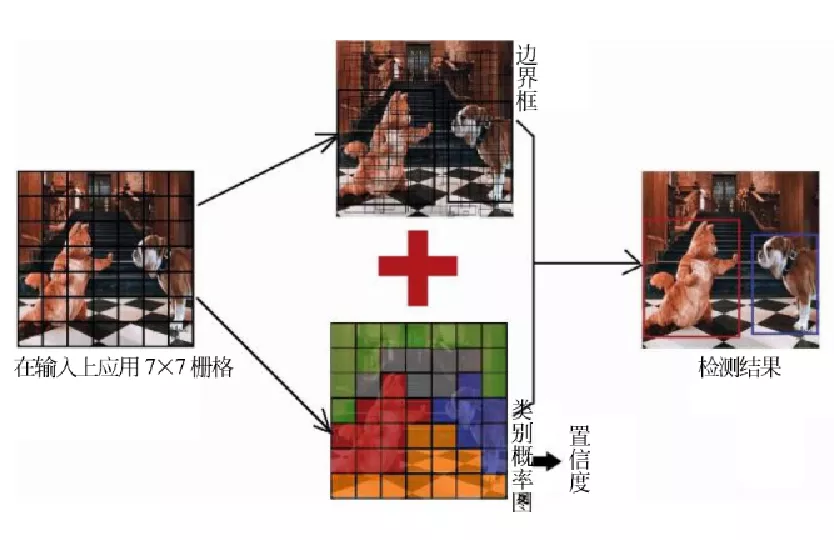
2015年Redmon等人提出了YOLO算法,将分类、定位、检测功能融合在一个网络当中,输入图像只需要经过一次网络计算,就可以直接得到图像中目标的边界框和类别概率。
基本步骤
- 一幅图片分成s*s个网格(grid cell),如果某个目标的中心点落在某个网格里,那么该网络负责预测该物体。
- 每个网格预测B个bounding box,每个bbox除了要预测bbox的位置外,还要预测一个置信度(confidence)的值每个网格还要预测c个类别的分数。
原论文里,s = 7,B = 2,c = 20
网络结构
整体结构:

最终输出7x7x30的张量的结构图为:
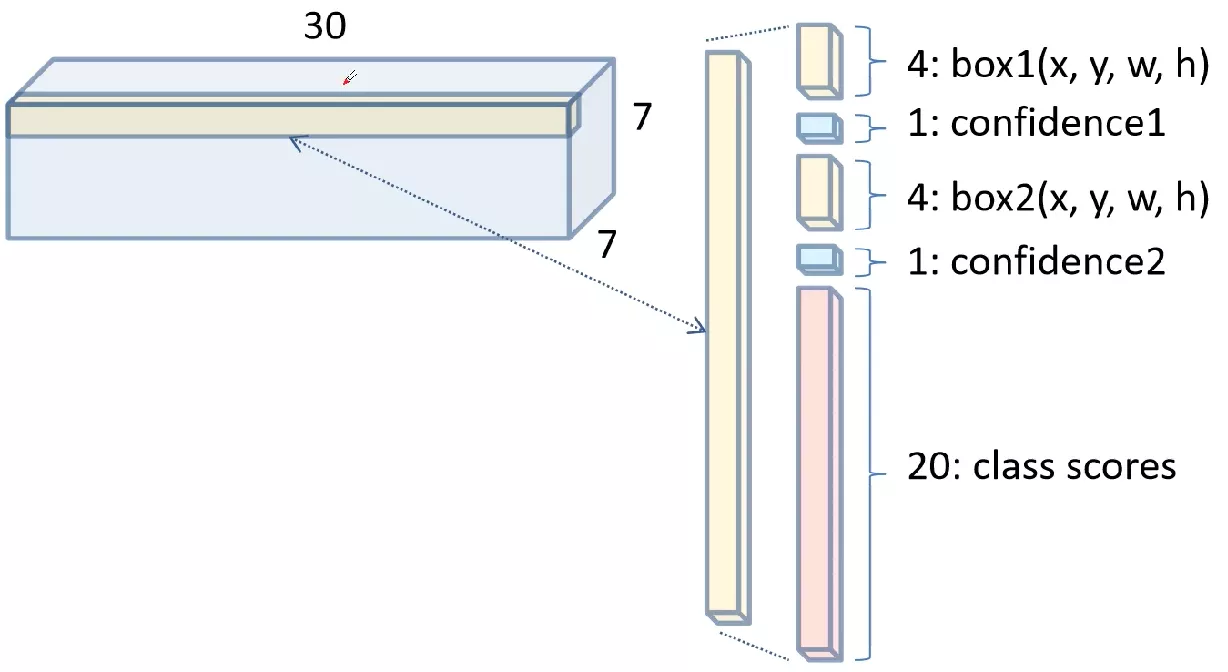
其中7为最初每张图片分成7x7个网格。每个bounding box预测四个位置信息,一个置信度信息,一个网格预测两个bounding box,所以,一个网格包含十个特征信息。又因为共预测20类目标,所以还有二十个类别信息,因此,一共20+10=30个信息。
优缺点
优点:
- Yolo采用一个CNN网络来实现检测,是单阶段检测框架,所以Yolo算法比较简洁且速度快。
- 由于Yolo是对整张图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判。
缺点:
- 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,或每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
YOLO的演变
为了克服 YOLO v1 检测速度快,但检测精度低的问题, YOLO v2算法引入BN ( batch normalization) 、多尺度训练、锚框机制和细粒度特征等方法对YOLO v1 算法进行改进。YOLO v3算法在YOLO v2 的基础上,采用更好的主干网络、多尺度预测和 9 个锚框进行检测,使得检测算法在保证实时性的同时,精度提高。近几年又发展出了yolo v4,yolo v5网络。
SSD
2016 年 Liu 等人提出了 SSD 算法,在回归思想的基础上,有效结合多尺度检测的思想,提取多个不同尺度的特征图进行检测,遵循较大的特征图用来检测相对较小的目标,较小的特征图检测较大目标的策略,显著提高了对大目标的检测效果,对小目标检测也有一定的提升。
基本步骤
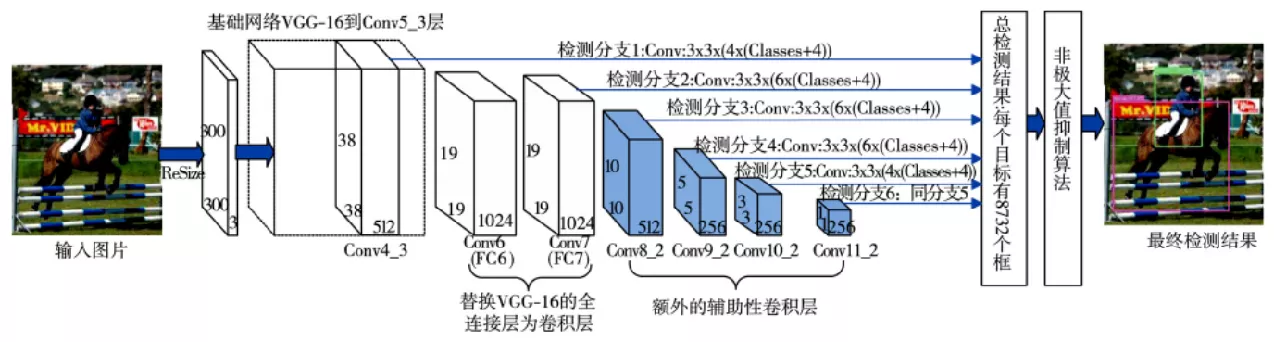
VGG-16模型:
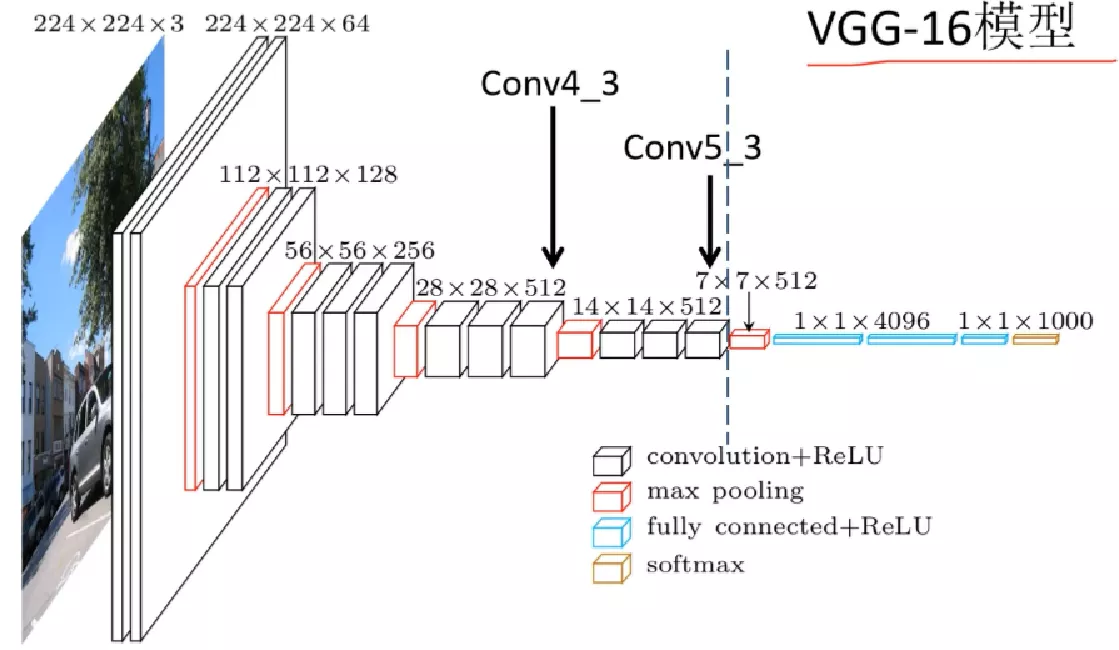
优缺点
优点:
- 将不同层次的特征图进行融合,提升了速度和检测精度。
缺点:
- 但 SSD 算法提取的不同卷积层特征独立输入各自的检测分支,容易出现同一个物体被不同大小的边界框同时检测出来的情况,即重复检测问题。而 且每层的检测分支仅关注自己分支上特定尺度的目标,没有考虑到 不同层、不同尺度目标间的关联性,所以对小目标检测效果一般。






